
Photo by Artturi Jalli on Unsplash
How to Scrape tweets from Twitter using the Twint Scraping tool with Python
Using data scraping tools, you can compile millions of data in a few seconds.


Introduction: How Data Scraping is Changing the Narrative
Data scraping is a process in which data is extracted from websites or other sources and transformed into a format that can be used for further analysis. This technique is often used by businesses and organizations to collect large amounts of data from the internet, such as product pricing information, consumer behavior data, or market research.
The use of data scraping has allowed businesses and organizations to gather and analyze large amounts of data in a much more efficient and cost-effective way than would be possible manually. This has enabled them to gain valuable insights that can help inform their decision-making and improve their operations.
This Tutorial will provide a step-by-step guide on scraping data from Twitter using Twint with Python.
What you will need for this Tutorial
- Basic knowledge of Python
- CMD
- Beautiful soup 4
- Python 3.6 or later
- PIP
- Twint Library
Note: I will be using a windows computer (Windows 11 Dev) for this Tutorial.
Step 1: Set up a virtual environment
Organizing your files makes coding enjoyable. Before you start any coding process, although optional, it is important to create a virtual environmentwhere you can store all the files related to the project.
To Create a virtual environment:
- Create a Folder with a name of your choice. E.g.‘Tutorial’
- Open Command Prompt and run the code below in the path where you want to create your virtual environment:
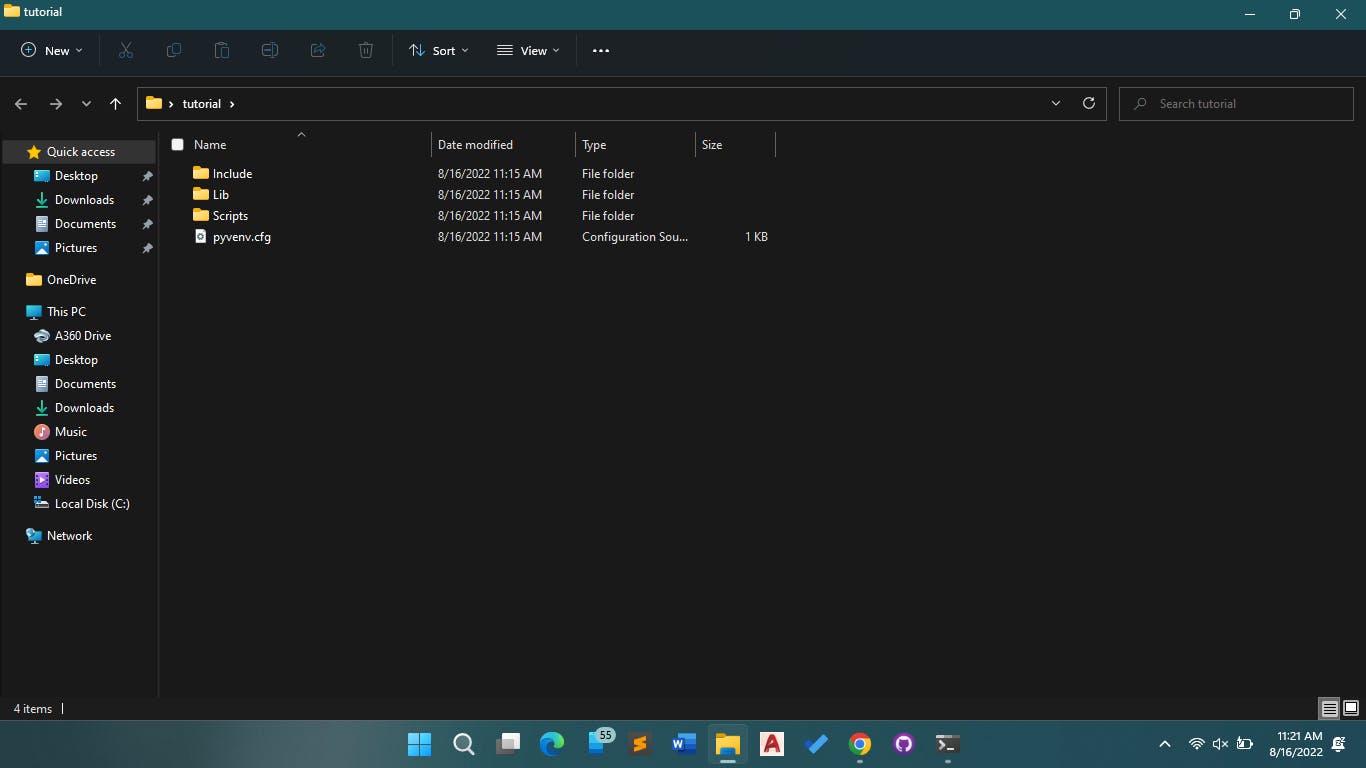
py -m venv "C:\Users\F I S I O N\Desktop\tutorial"
If done correctly, you should have something like the image below:
Step 2: Install the Twint Library
The Next thing is to install the twint library. The twint library allows you to scrape unlimited tweeter data without using Twitter’s official API. Run the code below to install the package.
pip install Twint
To check that Twint is installed successfully, type the code:
pip list
Step 3: Import Twint and scrape your data
The next step is to import the Twint library and run the code for a target keyword to scrape your data. For this Tutorial, we want to scrape all tweets with the phrase ‘tech writer’.
import twint
c = twint.Config()
c.Search = ['Tech Writer'] # keyword
c.Limit = 500 #scrape limits
c.Store_csv = True # To store tweets in a csv file
c.Output = "tech_writer_tweets.csv" #csv file where the scraped data will be stored
twint.run.Search(c)
Twint Configurations
You can tweak the scraped data based on other parameters such as time, region, etc., by using the configurations below:
#configuration settings for Twint
config = twint.Config()
config.Search = "Tech Writer"
config.Lang = "en"
config.Limit = 500
config.Since = "2022–05–01"
config.Until = "2022–08–16"
config.Store_json = True
config.Output = "custom_out.json"
twint.run.Search(config)
Terms
- Search = Keyword
- Lang: Language of Preference
- Limit: Scrape Limit
- Since and Until: Date
Final Words
You can use the Twint Library to scrape Twitter data in several ways. To learn more about theTwint library, visit the official twint GitHub page here. Thank you for reading.